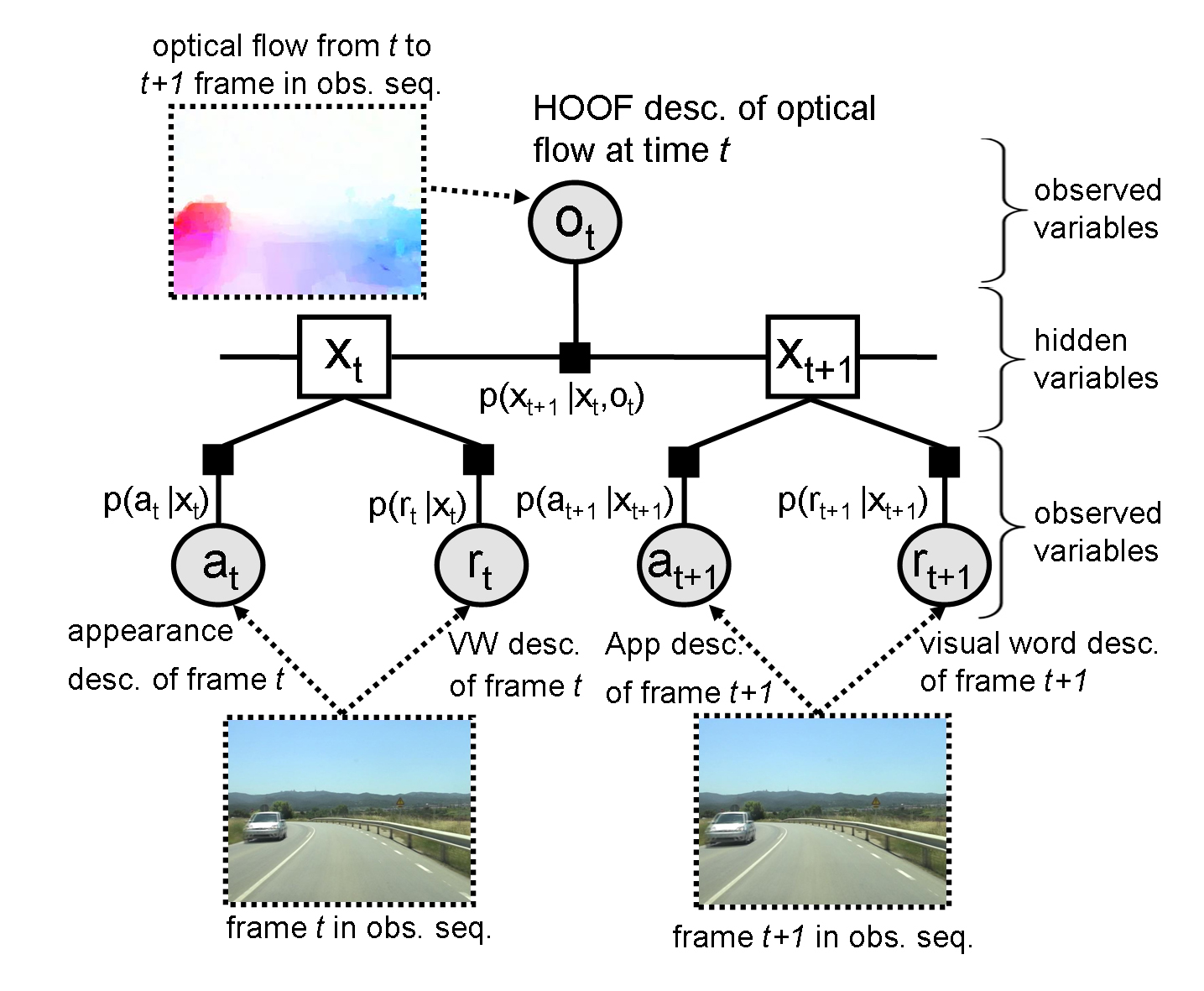
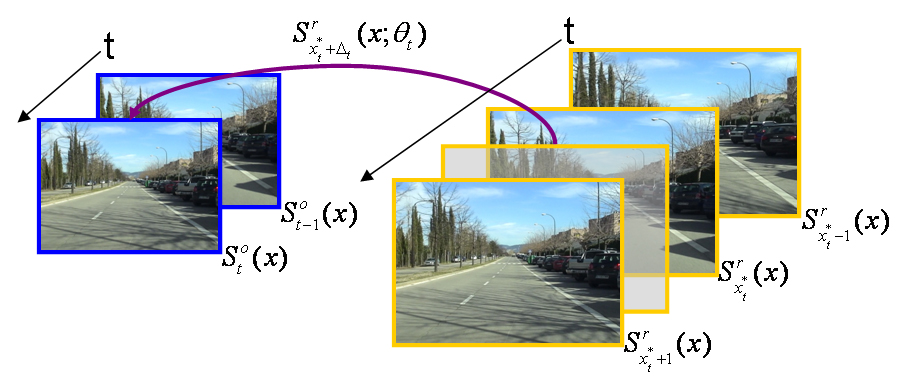
Video alignment relates two video sequences in both their spatial and temporal dimensions. In spite of being relatively unknown, it has been successfully employed in different areas of computer vision such as wide baseline matching, action recognition, sensor fusion, change detection, frame dropping prevention and scene labelling. Current video alignment algorithms deal with the relative simple cases of cameras fixed or rigidly attached to each other recording simultanously the same scene. In this paper, a novel subframe video alignment is proposed to deal with the challenging problem of aligning sequences recorded at different times by independently moving cameras. In particular, the estimation of a frame correspondence is based on multiple visual cues in a dynamic Bayesian network (DBN). That visual cues consists of image appearance, visual words and dense motion field descriptors in order to exploit the intra-- and inter-- sequence spatio--temporal similarities. Once a temporal mapping is estimated, the spatial alignment is estimated jointly with the refinement of frame correspondence with subframe accuracy. The video alignment accuracy is quantitatively evaluated on three pairs of video sequences recorded at different scenarios. More than approximately 85% of frames have, at most, one frame of synchronization error. |
|


