Abstract
In this chapter, we pose the problem of aligning two video sequences recorded by independently moving cameras that follow similar trajectories as a MAP inference problem on a Bayesian network, based only on the fusion of image intensity and GPS information. The Bayesian framework is a principled way to integrate the observations from these two sensor types, which have been proved complementary. Alignment results are presented in the context of videos recorded from vehicles driving along the same track at different times, for different road types. In addition, we explore two applications both needing change detection between aligned videos. One is the detection of vehicles, which could be of use in ADAS. The other is the difference spotting for on--board surveillance. |
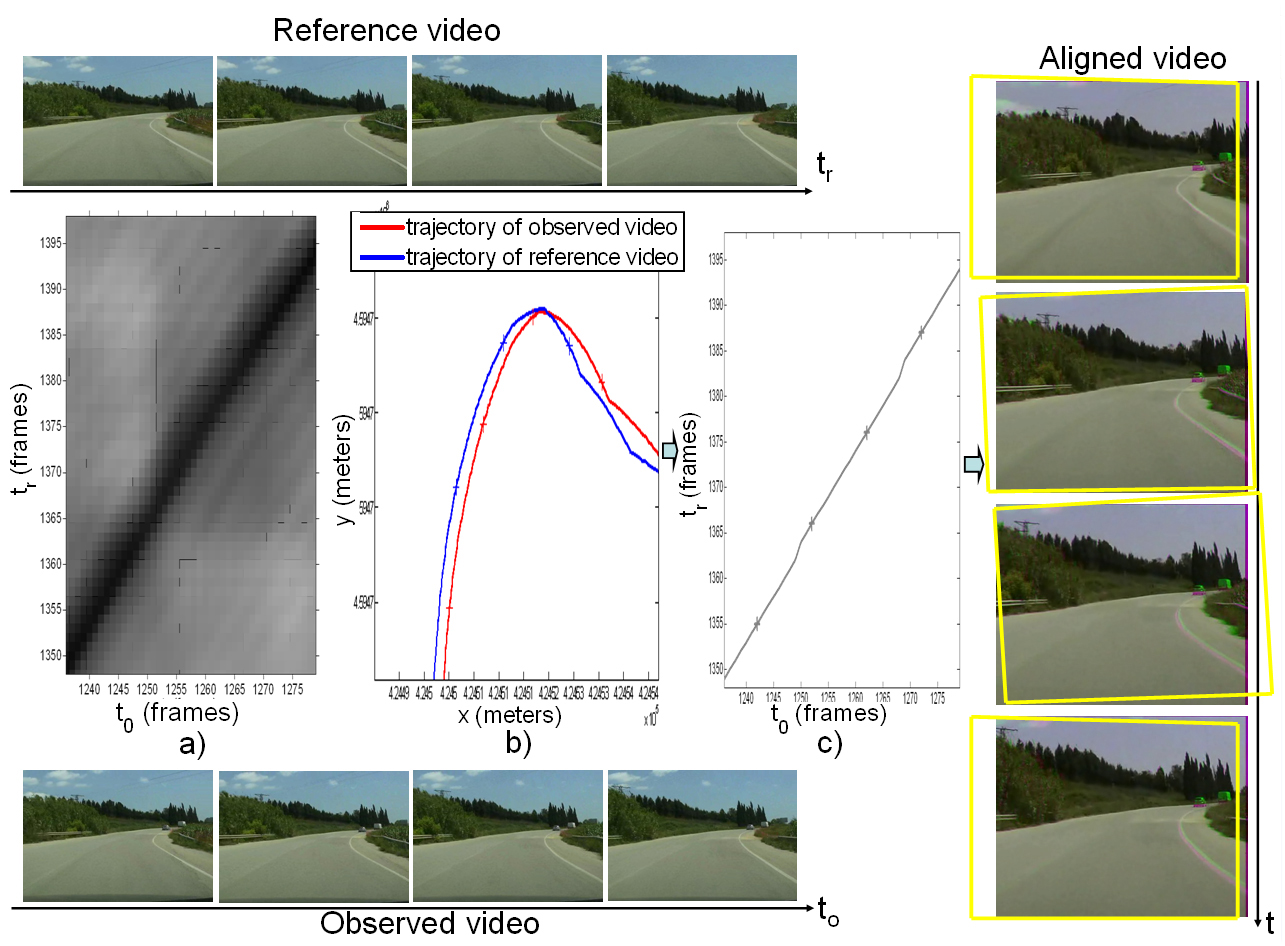
|
Sequences
We have aligned eight video sequence pairs. These sequences were recorded with a SONY DCR--PC330E camcorder in different environments: a university campus during the day ('campus' pair) and at night ('night' pair), a suburban street, a back road and a highway. These sequence pair can be divided into two groups:
In the first one, containing one pair per scenario (labeled as 'campus1', 'backroad1', 'highway1', 'night', 'street'), sequences were recorded while driving at 'normal' velocity at each point of the track. We mean that we did not try intentionally to maintain a constant speed along the whole sequence, or even to drive with a similar speed in the reference and the observed sequence at a given point. Instead, we drove independently in all the reference and observed sequences, adjusting the speed at each moment to the road type and geometry, and to the traffic conditions. In consequence, in all of these pairs the instantaneous velocities of the reference and observed sequences are not equal, though they tend to be close.
The second group is formed by the three pairs 'campus2', 'backroad2' and 'highway2'. These were recorded with the intent of generating frequent and large velocity differences at the same location between the reference and the observed sequence. They contain points that do not correspond to a normal driving profile because of frequent and sharp acceleration and braking. Therefore, these pairs may be more challenging to synchronize.
Campus-1
Original Videos
|
Synchronized Videos
|
Difference of Aligned Videos
|
Fusion of Aligned Videos
|
Highway-1
Original Videos
|
Synchronized Videos
|
Difference of Aligned Videos
|
Fusion of Aligned Videos
|
Backroad-1
Original Videos
|
Synchronized Videos
|
Difference of Aligned Videos
|
Fusion of Aligned Videos
|
Street
Original Videos
|
Synchronized Videos
|
Difference of Aligned Videos
|
Fusion of Aligned Videos
|
Night
Original Videos
|
Synchronized Videos
|
Difference of Aligned Videos
|
Fusion of Aligned Videos
|
Campus-2
Original Videos
|
Synchronized Videos
|
Difference of Aligned Videos
|
Fusion of Aligned Videos
|
Highway-2
Original Videos
|
Synchronized Videos
|
Difference of Aligned Videos
|
Fusion of Aligned Videos
|
Backroad-2
Original Videos
|
Synchronized Videos
|
Difference of Aligned Videos
|
Fusion of Aligned Videos
|
Vehicle Detection
Comparison w.r.t. Sand & Teller algorithm [1]
[1] Peter Sand and Seth Teller, Video Matching in ACM Transactions on Graphics (Proc. SIGGRAPH), Vol. 22, No. 3, July 2004, pp. 592-599.
Original Videos
|
Sand & Teller algorithm
|
Our method
|
Synthetic Road
The synthetic results have been used to validate the temporal and spatial registration with regard to a ground truth.
Original Videos
|
Synchronization
|
Video Alignment
|


