| Title | Cross and Learn: Cross-Modal Self-Supervision |
| Publication Type | Conference Paper |
| Year of Publication | 2018 |
| Authors | Sayed, N, Brattoli, B, Ommer, B |
| Conference Name | German Conference on Pattern Recognition (GCPR) (Oral) |
| Conference Location | Stuttgart, Germany |
| Keywords | action recognition, cross-modal, image understanding, unsupervised learning |
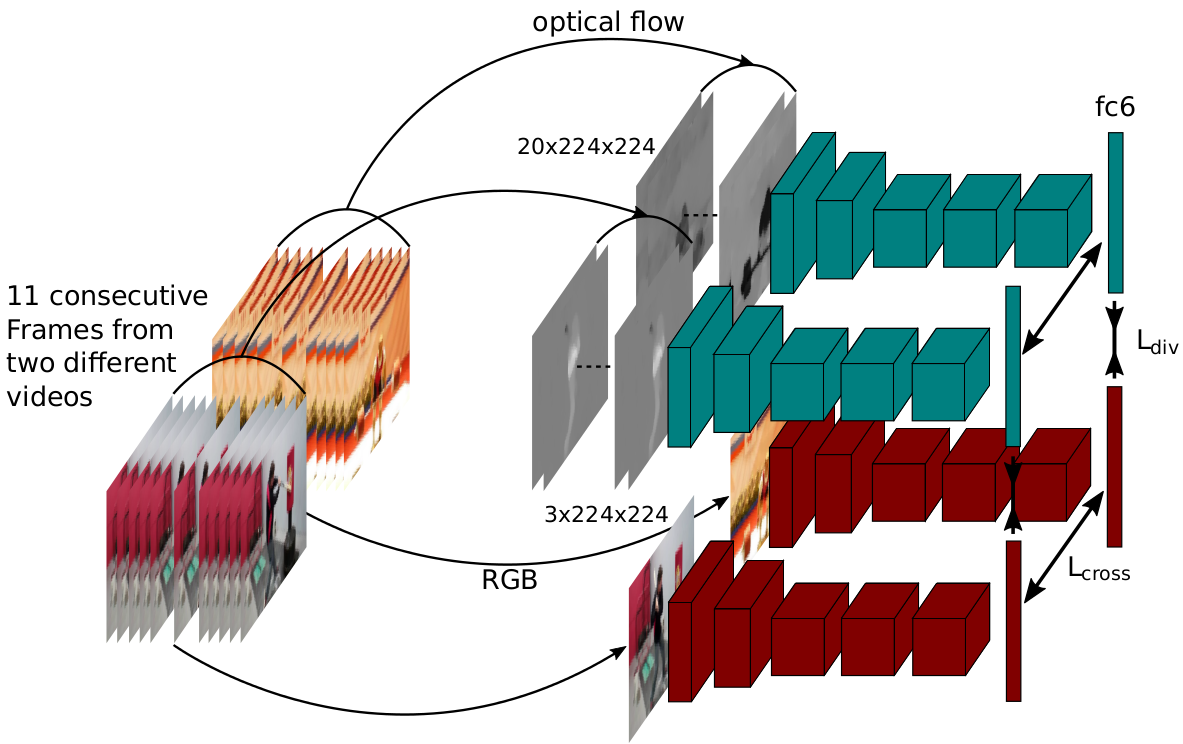
| Abstract | In this paper we present a self-supervised method to learn feature representations for different modalities. Based on the observation that cross-modal information has a high semantic meaning we propose a method to effectively exploit this signal. For our method we utilize video data since it is available on a large scale and provides easily accessible modalities given by RGB and optical flow. We demonstrate state-of-the-art performance on highly contested action recognition datasets in the context of self-supervised learning. We also show the transferability of our feature representations and conduct extensive ablation studies to validate our core contributions. |
| URL | https://arxiv.org/abs/1811.03879v1 |
| Citation Key | sayed:GCPR:2018 |