



Chamfer matching is an effective and widely used technique for detecting objects or parts thereof by their shape. However, a serious limitation is its susceptibility to background clutter. The primary reason for this is that the presence of individual model points in a query image is measured independently. A match with the object model is then represented by the sum of all the individual model point distance transformations. Consequently, i) all object pixels are treated as being independent and equally relevant, and ii) the model contour (the foreground) is prone to accidental matches with background clutter.
As demonstrated by Attneave [1], and various experiments on illusionary contours, object boundary pixels are not all equally important due to their statistical interdependence. Moreover, in dense background clutter the points on the model have a high likelihood to find good spurious matches [1, 3]. However, any arbitrary model would match to such a cluttered region, which consequently gives rise to matches with high accidentalness. Chamfer matching only matches the template contour and thus fails to discount the matching score by the accidentalness, i.e., the likelihood that this is a spurious match.
Processing Pipeline
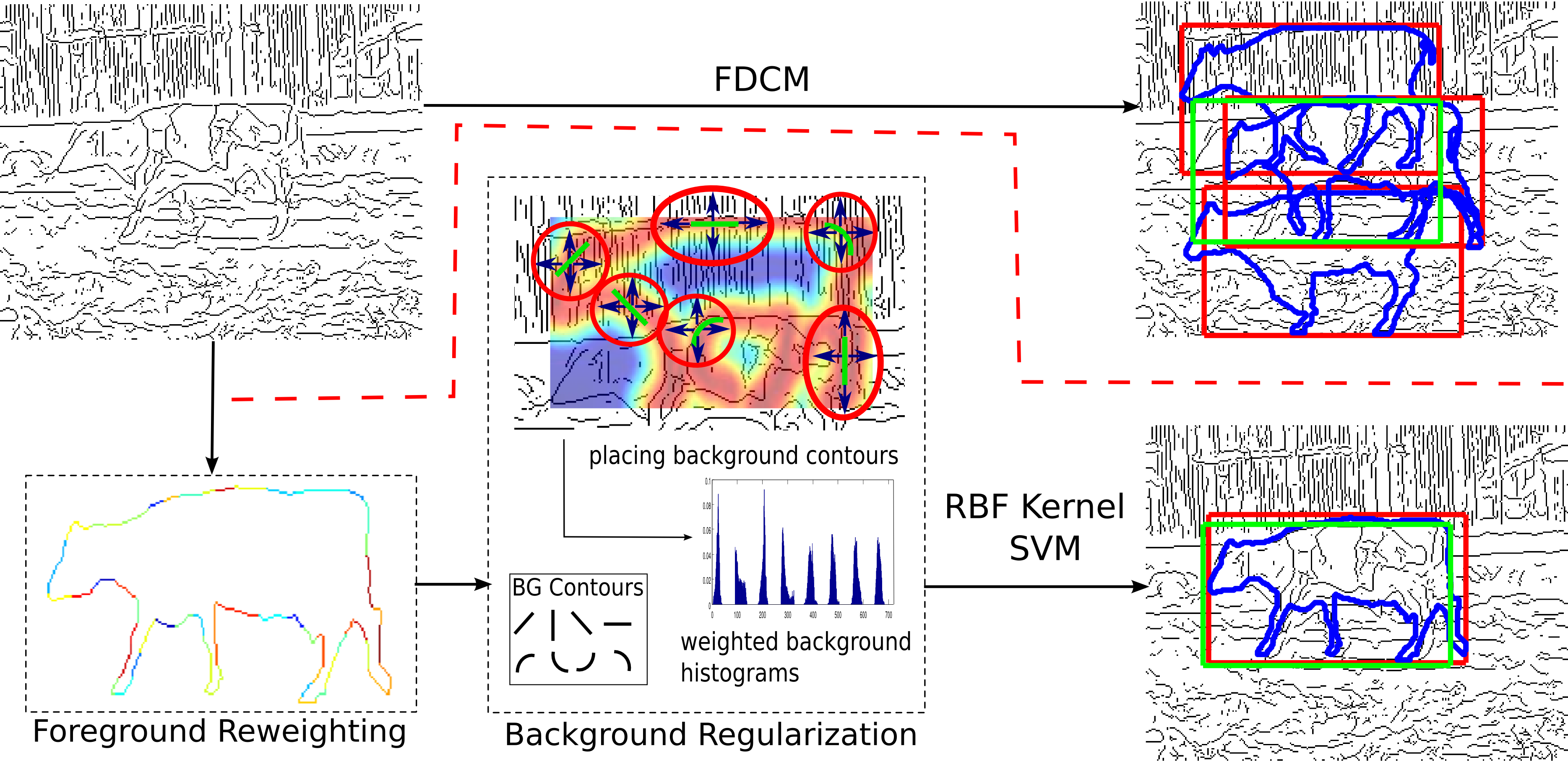
We take account of the fact that boundary pixels are not all equally important by applying a discriminative approach to chamfer distance computation, thereby increasing its robustness. Let $T = \{t_i\}$ and $Q = \{q_i\}$ be the sets of template and query edge map respectively. Let $\phi(t_i)$ denote the edge orientation of the edge point $t_i$. For a given location $x$ of the template in the query image, directional chamfer matching [1] finds the best $q_j \in Q$ for each $t_i \in T$, thus resulting in a matching cost ${{p_i}^{(T, Q)}}(x)$.
$${{p_i}^{(T, Q)}}(x) = \min_{q_j \in Q}|(t_i - x) + q_j| + \lambda|\phi(t_i + x) - \phi(q_j)| .......... (1)$$Adjacent template pixels are statistically dependent and, thus, we do average Eq.1 over the direct neighbors of pixel. The resulting are then used to learn the importance of contour pixels.

While learning the weights for individual pixels improves the robustness of template matching, chamfer matching is still prone to accidental responses in spurious background clutter. To estimate the accidentalness of a match, a small dictionary of simple background contours $T_{bg}$ is utilized. Rather than placing background contours at a fixed single location, i.e., at the center of the model contour as in [3], background elements are trained to focus at locations where, relative to the foreground, typically accidental matches occur.
Let ${d_{DCM}^{(T, Q)}}(x)$ denote the directional chamfer distance between $Q$ and $T$ with a relative displacement $x$. To measure where clutter typically interferes with the model contour we compute ${d_{DCM}^{(T_{bg}, T)}}(x)$ between each background contour $T_{bg}$ and the object template $T$. We consider placements of the background contour with better (lower) chamfer matching score to be more important since they occur on or close to the model contour. In order to weight these matching locations higher we create a mask ${M^{(T_{bg}, T)}}(x)$
$${M^{(T_{bg}, T)}}(x) = 1 - {d_{DCM}^{(T_{bg}, T)}}(x) .......... (2)$$To describe the background matching costs for a hypothesis in a robust way we build weighted histograms over chamfer matching scores ${d_{DCM}^{(T_{bg}, Q)}}(x)$ obtained from matching a background contour $T_{bg}$ with the query image $Q$. Let $B(\bar x)$ be the bounding box region with center \bar x for a specific placement of the foreground template $T$ in the query image $Q$. For each foreground hypothesis we build weighted histograms $h^{(T_{bg}, Q)}$ over the directional chamfer matching scores ${d_{DCM}^{(T_{bg}, T)}}(x)$ in the corresponding bounding box region. The weights introduced in ${M^{(T_{bg}, T)}}(x)$ are used to weight the histogram votes. Therefore chamfer matching scores $h^{(T_{bg}, Q)}$ are weighted according to their position relative to the foreground template. Each histogram consists of $K$ bins where $\mathscr{M}_k$ is the range of the kth bin and $k = 1,2,...,K$. A histogram bin $h_k^{(T_{bg}, Q)}$ is defined as
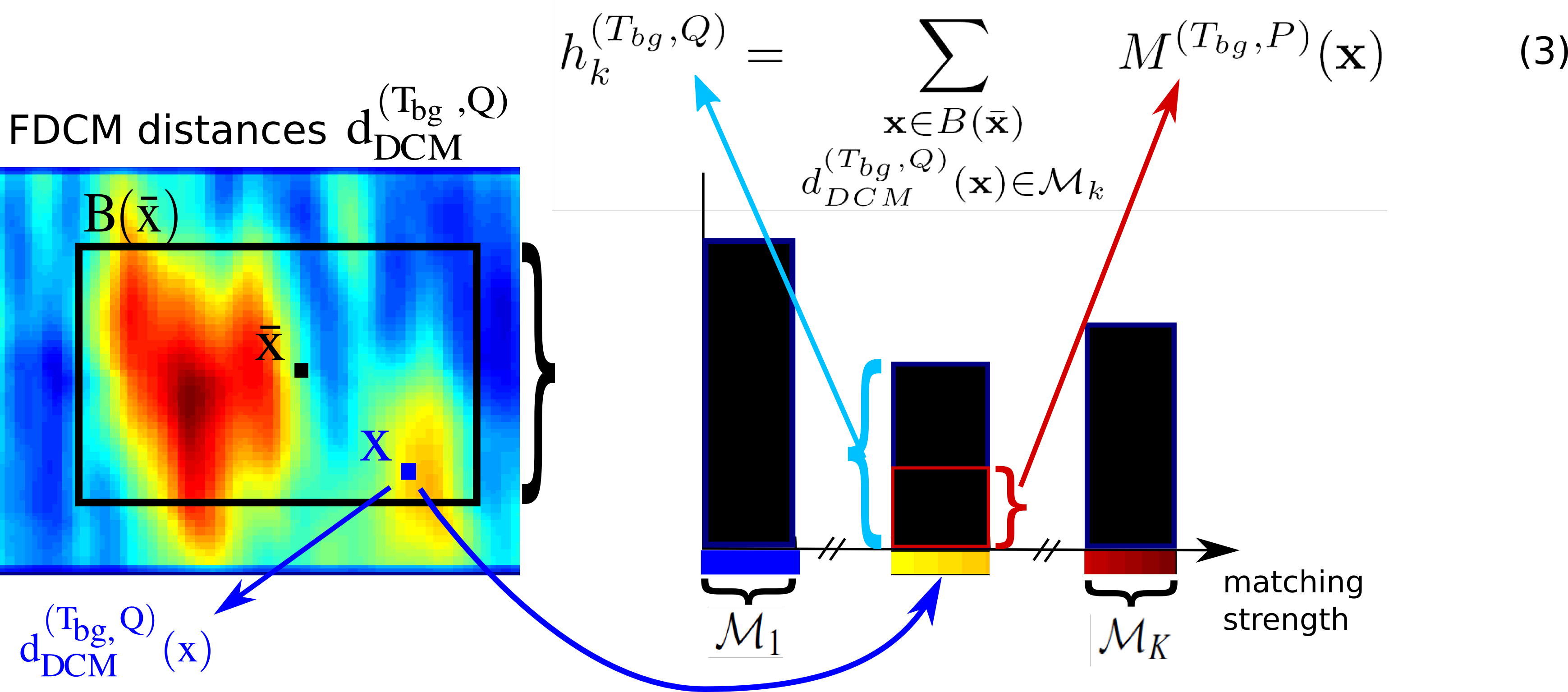
for each background contour $T_{bg}$ on a certain position of the foreground template $T$ in the query image $Q$.
For each object hypothesis we build a feature vector $f_i = [\bar p_1 ... \bar p_L, h_1 ... h_G]$ consisting of the average pixel cost $\bar p_i$ and the corresponding background histograms $h_i$ , where $L$ is the number of template edge pixels and $G$ is the number of background contours.
Finally, a max-margin classifier is employed to learn the co-placement of all background contours and the foreground template. This classifier yields a regularized distance function $d_{RDCM}$
$${d_{RDCM}^{(T, Q)}}(x) = 1 - \left({\sum_i \alpha_i \mathcal{K}(f_j, S_i) + b}\right) .......... (4)$$ $\mathcal{K}$ denotes the kernel used in the SVM. $b$ denotes the offset. $S_i$, $\alpha_i$ denotes the support vectors and their respective coefficients.Our approach is easily integrated into an off-the-shelf directional chamfer matching approach and it shows significant improvements over state-of-the-art chamfer matching on standard benchmark datasets. The qualitative and quantitative results are detailed in the paper.
Results
For our experimental evaluation, we use the TUD Pedestrians, TUD Cows and the ETHZ Shape data sets. Comparison of average precision for three data sets namely, TUD Pedestrians, Cows and the ETHZ Shape classes. We compare DCM [1] which constitutes the basis of our approach with the suggested foreground re-weighting and our final learning of regularized chamfer matching. All the detections are evaluated based on PASCAL overlap criterion with the ground truth object annotations.

Publications
Angela Eigenstetter*, Pradeep Yarlagadda*, and Björn Ommer,Max-Margin Regularization for Reducing Accidentalness in Chamfer Matching,
in: ACCV'12, Springer, 2012 (* indicates equal contribution, accepted, in press). [Poster]
Pradeep Yarlagadda*, Angela Eigenstetter*, and Björn Ommer,
Learning Discriminative Chamfer Regularization,
in: BMVC'12, 2012 (* indicates equal contribution, accepted, in press).
References
- F. Attneave. Some informational aspects of visual perception. Psych. Review, 61(3), 1954.
- M. Liu and O. Tuzel and A. Veeraraghavan and R. Chellappa. Fast Directional Chamfer Matching. In CVPR, 2010.
- T. Ma and X. Xang and L. Latecki. Boosting Chamfer Matching by Learning Chamfer Distance Normalization. In ECCV, 2010.