


This web page contains the supplemental material of the dissertation submitted at Universitat Autònoma de Barcelona to fulfil the requirements for the degree of Doctor of Philosophy.
Abstract
Video alignment consists of integrating multiple video sequences recorded independently into a single video sequence. This means to register both in time (synchronize frames) and space (image registration) so that the two videos sequences can be fused or compared pixel-wise. In spite of being relatively unknown, many applications today may benefit from the availability of robust and efficient video alignment methods. For instance, video surveillance requires to integrate video sequences that are recorded of the same scene at different times in order to detect changes. The problem of aligning videos has been addressed before, but in the relatively simple cases of fixed or rigidly attached cameras and simultaneous acquisition. In addition, most works rely on restrictive assumptions which reduce its difficulty such as linear time correspondence or the knowledge of the complete trajectories of corresponding scene points on the images; to some extent, these assumptions limit the practical applicability of the solutions developed until now. In this thesis, we focus on the challenging problem of aligning sequences recorded at different times from independent moving cameras following similar but not coincident trajectories. More precisely, this thesis covers four studies that advance the state-of-the-art in video alignment. First, we focus on analyzing and developing a probabilistic framework for video alignment, that is, a principled way to integrate multiple observations and prior information. In this way, two different approaches are presented to exploit the combination of several purely visual features (image-intensities, visual words and dense motion field descriptor), and global positioning system (GPS) information. Second, we focus on reformulating the problem into a single alignment framework since previous works on video alignment adopt a divide-and-conquer strategy, i.e., first solve the synchronization, and then register corresponding frames. This also generalizes the 'classic' case of fixed geometric transform and linear time mapping. Third, we focus on exploiting directly the time domain of the video sequences in order to avoid exhaustive cross-frame search. This provides relevant information used for learning the temporal mapping between pairs of video sequences. Finally, we focus on adapting these methods to the on-line setting for road detection and vehicle geolocation. The qualitative and quantitative results presented in this thesis on a variety of real-world pairs of video sequences show that the proposed method is: robust to varying imaging conditions, different image content (e.g., incoming and outgoing vehicles), variations on camera velocity, and different scenarios (indoor and outdoor) going beyond the state-of-the-art. Moreover, the on--line video alignment has been successfully applied for road detection and vehicle geolocation achieving promising results.
Methods
The outline of the methods presented in this dissertation and their result webpages are as:
| Synchronization as an inference problem, fusing image intensity and GPS information (VA Framework) | |
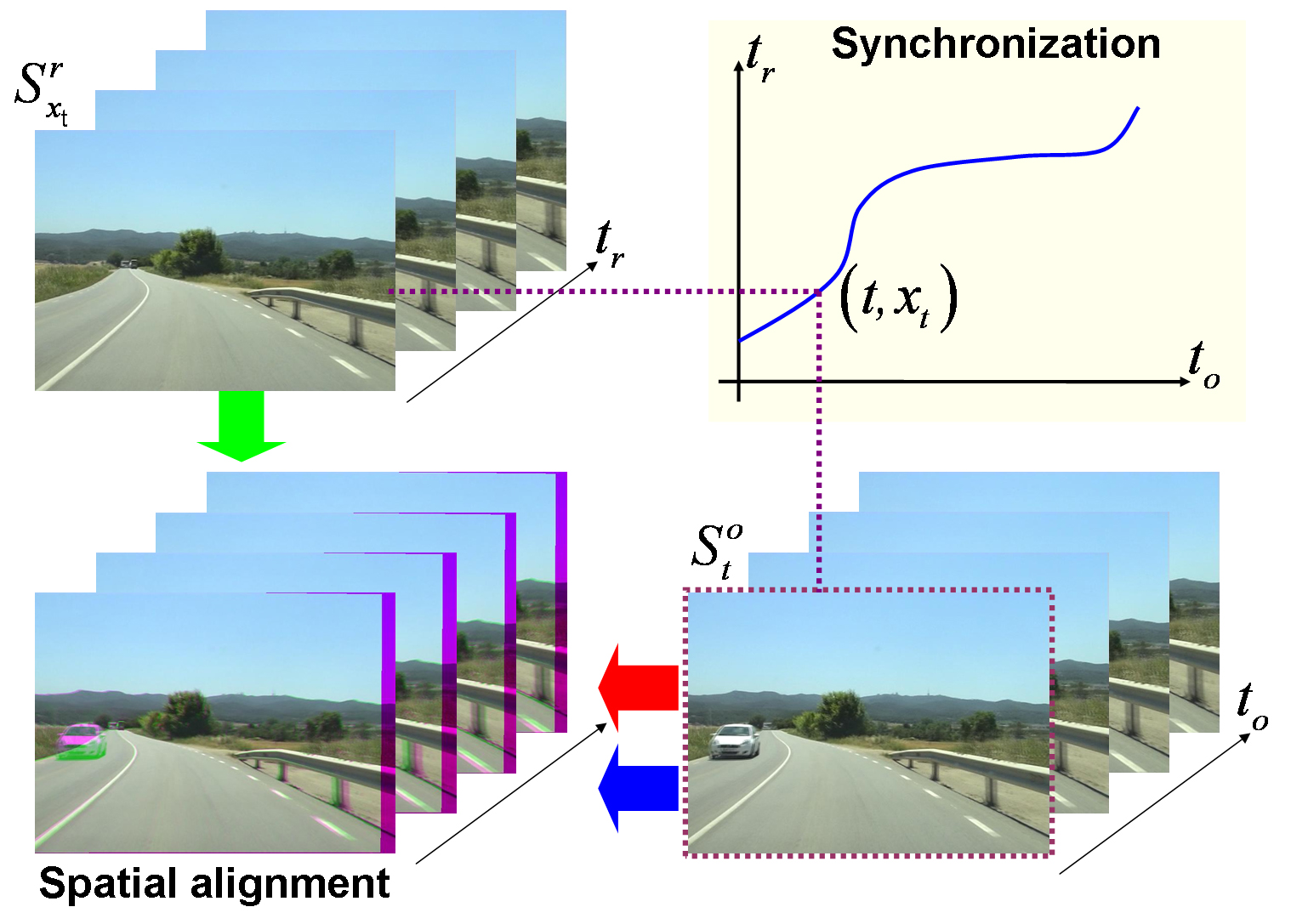
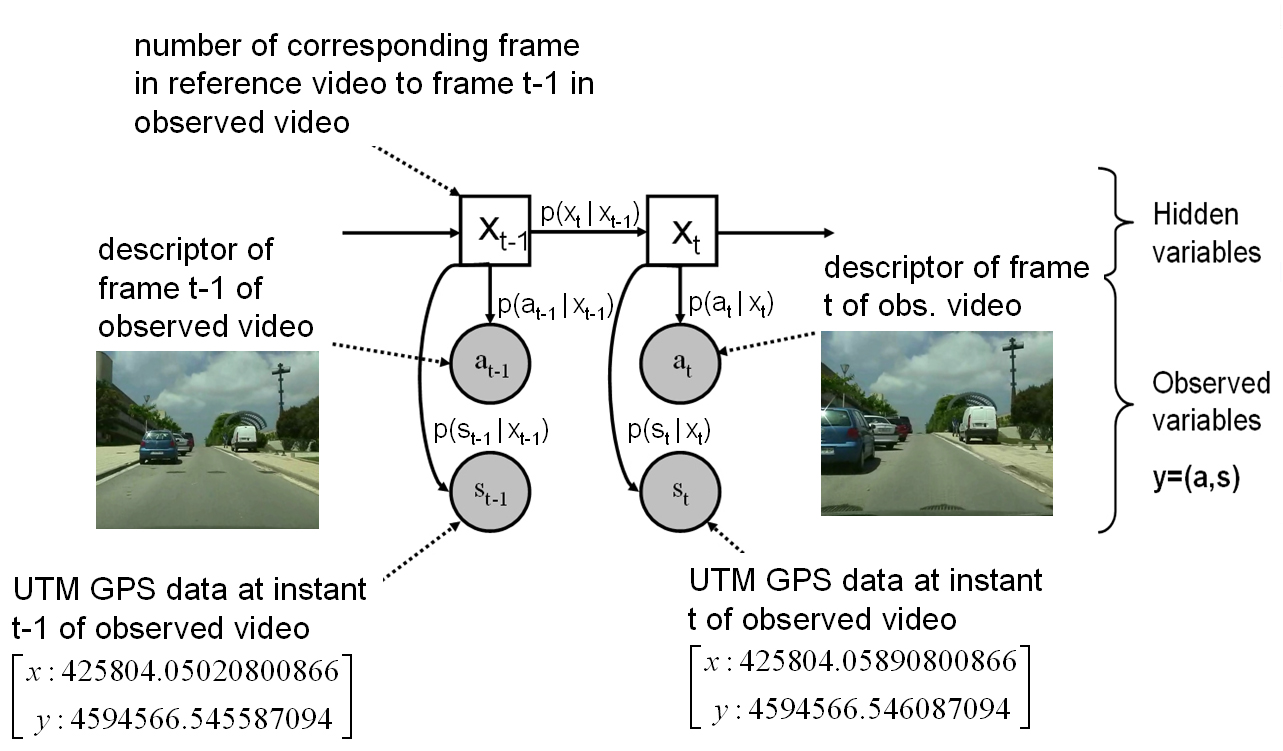
| In Chap. 3 , we formulate the video synchronization as a maximum a posteriori inference problem on a dynamic Bayesian network (DBN). More specifically, synchronization is posed as an inference of the most likely temporal mapping relying only on image intensities and GPS information. This approach has the advantage that the problem assumptions, image similarity and the GPS receiver position proximity can be expressed in probabilistic terms. The formulation introduced in this chapter is then used along the dissertation. We explore two applications needing change detection between aligned videos. |
| Synchronization relying only on multiple visual cues and refinement with subframe accuracy (Subframe VA) | |
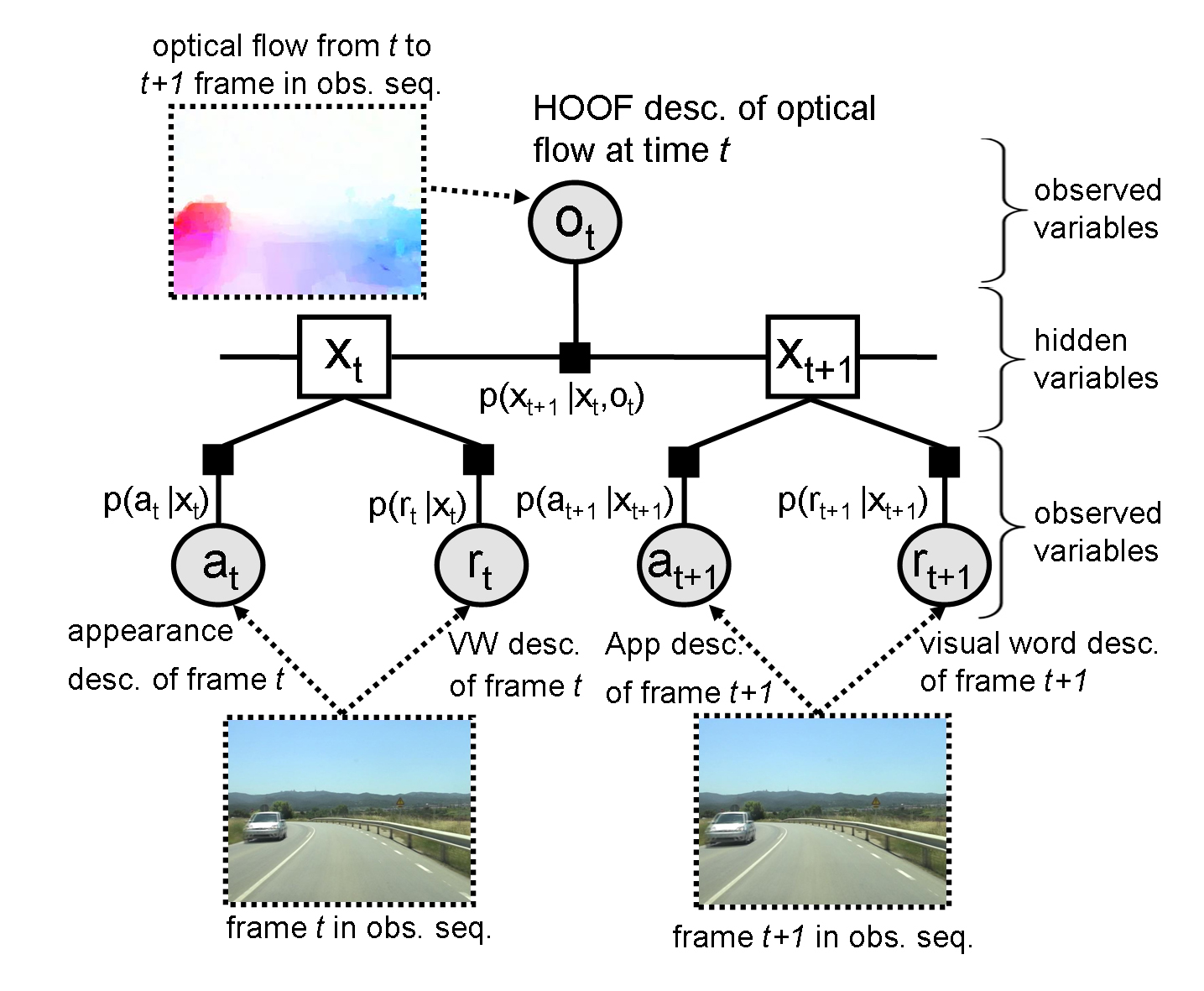
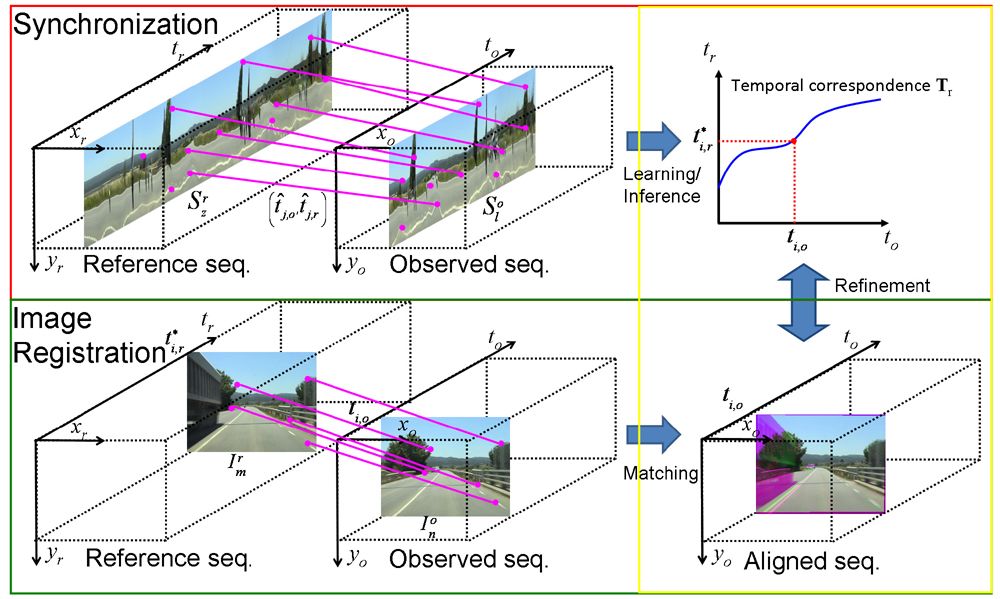
| In Chap. 4 we extend the above video synchronization method by relying just on the combination of several purely visual features and discarding other non--visual measurements like GPS observations, in spite that they help considerably to disambiguate the time correspondence. We have chosen visual features that exploit the similarities between video sequences in both the spatial (frame to frame) \emph{and} the temporal domain. We require not only that the content of corresponding frames is similar, but that local intra--sequence motion is, too. Another novelty is that the temporal correspondence is refined with subframe accuracy. In addition, we improve the accuracy of the spatial alignment by adapting a robust dense scene alignment technique. |
| Joint estimation of the spatio--temporal alignment exploiting the neighbor frames (Joint VA) | |
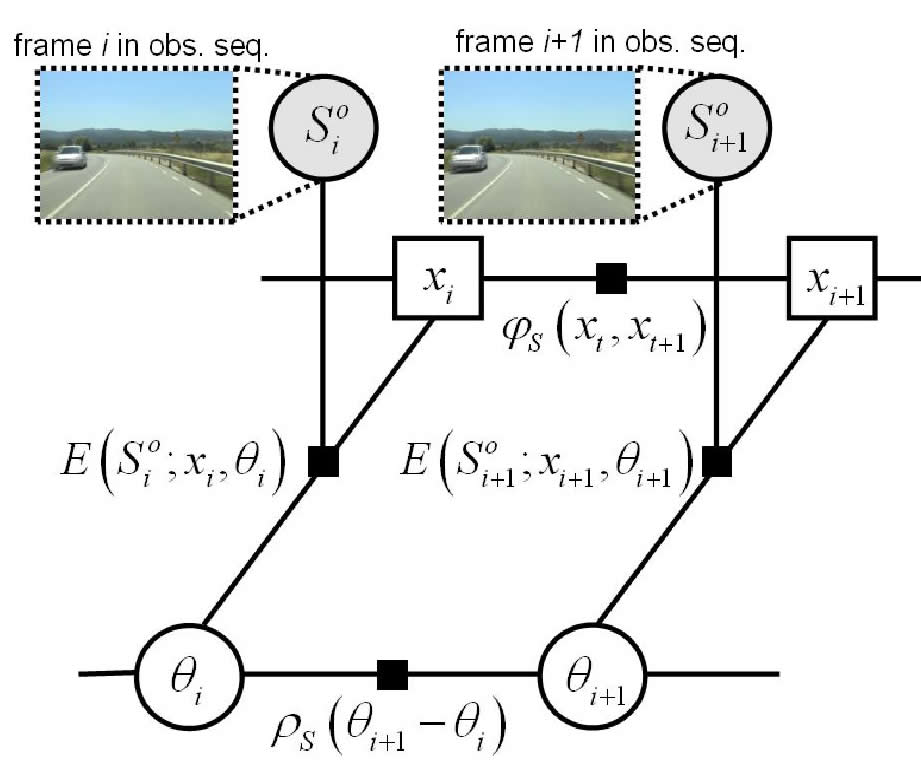
| Until now we have adopted a divide--and--conquer approach: the video alignment problem has been decomposed in two subproblems, namely, synchronization and frame registration, to be solved independently, for the sake of tractability. The shortcoming of this approach is that errors on the first step propagate to the second. Hence, in Chap. 5, we reformulate the problem as a simultaneous inference of both the time and spatial correspondence. Our new formulation generalizes the 'classic' case of fixed geometric transform and linear time mapping. |
| Learning the synchronization correspondence according to slice matching that works directly on temporal domain (Slice Matching) | |
| Instead of inferring the temporal correspondence based on frame similarities, in Chap. 6 we work directly on the temporal domain since the synchronization is based on slice matching. The key idea of the algorithm is to exploit the analogy between image matching and slice matching. Image matching provides putative spatial matches to estimate a geometric transformation; whereas slice matching provides putative temporal correspondences that can be used to estimate the temporal mapping. Furthermore, we learn the temporal correspondence based on that putative correspondences. This allows us to process new types of sequences, like indoor sequences, without manual parameter tunning. |
Applications
The outline of the applications based on Online Video Alignment presented in this dissertation and their result webpages are as:
| On-board Road Detection | |
| Road detection is an essential functionality for supporting advanced driver assistance systems (ADAS) such as road following and vehicle and pedestrian detection. The major challenges for detecting road areas in images are dealing with lighting variations and the presence of objects on the scene. Current road detection algorithms characterize road areas at pixel level and grouping them accordingly. However, these algorithms fail in presence of strong shadows and lighting variations. We propose a road detection algorithm that exploits the similarities occurred when a vehicle follows the same trajectory more than once. Thus, image areas depicting drivable road surfaces are inferred by transferring the knowledge learned previously. Then, video alignment is combined with a refinement step to provide the required accuracy. Experiments are conducted on different video sequences taken in different scenarios and daytime. Qualitative and quantitative evaluations prove that the proposed algorithm is robust to varying imaging conditions and scenarios. |
| Vehicle Geolocation | |
| Geolocation is a key component in automotive navigation systems or for managing fleets of vehicles. The most employed sensor for geolocation is the GPS receiver. Its accuracy may be drastically reduced in urban areas due to multiple reception path or satellite occlusions. In this chapter we propose a novel method for estimating the geospatial location of a vehicle based on on--line video matching. The key idea is to infer the vehicle location based just on visual information: assigning each newly acquired frame to a frame in the topological--map made of sequences so that they are acquired at the same position, and transfer the geospatial location of this retrieved frame to the recent frame. Moreover, we propose a qualified method to annotate the geospatial location for all the images in the map. The key advantages of the proposed vehicle geolocation are: 1) the increase of the rate and the accuracy of the vehicle position with regard to a consumer GPS and 2) the ability to localize a vehicle even when a GPS is not available or is not reliable enough, like in certain urban areas. Experimental results for urban environments on three different datasets are presented, showing an average of relative accuracy of 1.6 meters. |

